拉普拉斯方法
| 此条目翻译品质不佳。 (2014年5月19日) |
在数学上,以皮埃尔-西蒙·拉普拉斯命名的拉普拉斯方法是用于得出下列积分形式的近似解的方法:

其中的 ƒ(x) 是一个二次可微函数, M 是一个很大的数,而积分边界点 a 与 b 则允许为无限大。此外,函数 ƒ(x) 在此积分范围内的 全域极大值 所在处必须是唯一的并且不在边界点上。则它的近似解可以写为:

其中的 x0 为极大值所在处。这方法最早是拉普拉斯在 (1774, pp. 366–367) 所发表。(待考查)
拉普拉斯方法的想法概论
1. 相对误差
|
|---|
|
首先,我们得先知道的是,这里所谓的近似解是以 相对误差 在讲,而不是指 绝对误差 。因此,令 , 此 s 很显然的当 M 很大时为一个微小的数,则上述的积分可以写为 因此,我们的相对误差很显然的为 现在,让我们把积分分为 的与余下的部分。 |
2. 函数 在极大值附近的行为,当 很大时会趋近于
|
|---|
|
我们现在来研究 的 泰勒展开 。这里展开的原点取 x0 ,并将变数由 x 换为 y 因为我们是在对 y 做积分,再加上 x0 为函数极大值所在处,因此, |
{kind=link}
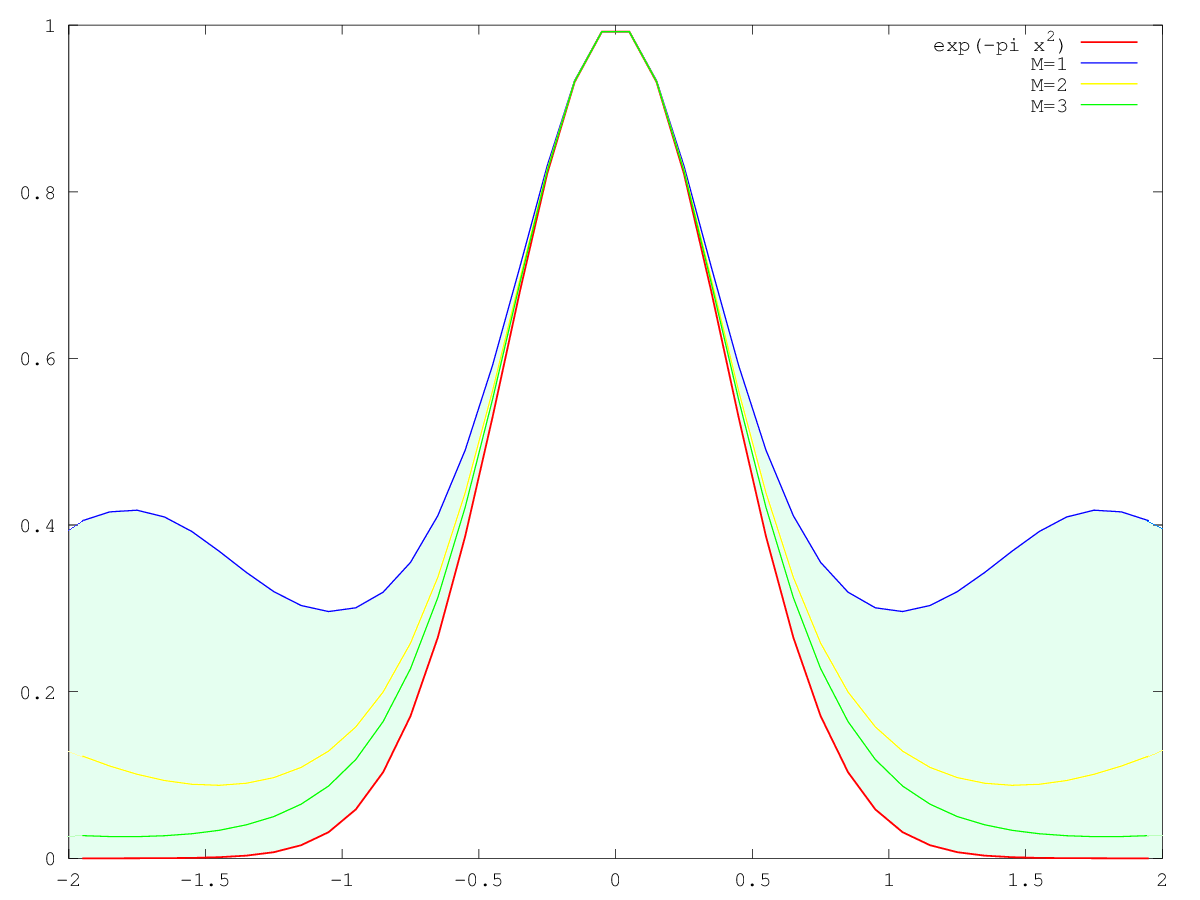
3. 当 增加,则相对应的 范围变小
|
|---|
的部分由上面論述可知當 M 越大則越接近高斯函數;並且有趣的是,相對應的 x 區間則越來越小,因為 與 成反比。 |
4.若拉普拉斯方法所用的积分会收敛,它的相对误差相对应的非极大值附近的其余部分的积分就会随 增大而趋近于0
|
|---|
|
所以,即便 Dy 取非常大, sDy 最后还是会变得非常小,那么,我们怎么保证余下的部分的积分也会趋近到0? 简单的想法是,设法找一个函数 ,使它在余下的区域内 ,并且随着 的增大, 的积分会趋近于0 即可。而指数函数只要指数部分为实数,它就一定大于0,并且当指数变大时,指数函数也会跟着变大。基于这两个理由, 的积分也会趋近于0。 在此,我们可以选择此 为过 的切线函数,如下图所示: 若为有限积分区间,我们可以看出,只要 够大,这切线的斜率就会趋近于0 ,因此,不管 在其余部分是否连续,它们总会在这切线以下,并且很容易证明(后面会证) 的积分当 很大时,就会趋近于0。 然而,若积分范围是无限大的话,那么, 就有可能总是与 有相交,若有相交,则表示无法保证 的积分最后会趋近于0。比方 的情形下,不管 为多少,它的 总是会发散。所以,对于积分范围为无限大的情形,还得要求 会收敛才行,那么,只要 越来越大,该积分就会趋近于0。而这 可选为 与 相交之处即可,即保证所有余下的部分的积分会趋近于0。 也许您会问说,为何不是要求 会收敛?举个例子,若 在余下区域内为 ,则 ,积分会发散,然而,当 , 的积分却是收敛的。所以,有的函数在 小的时候会发散,然而,当 够大时却会是收敛的。 |
.gif){kind=link}
基于上述四点,就有办法证明拉普拉斯方法的可靠性。而 Fog(2008) 又将此方法推广到任意精确。 ***待考查***
此方法的正式表述与证明:
假设 是一个在 这点满足 (1) ,(2)唯一全域最大,(3) 附近为二阶可微且 (4) 当拉普拉斯方法的积分范围为无限大时,此积分会收敛,
则,
证明:
|
|---|
|
下限 : 在 要求连续的条件底下,给定任意大于0的 就能找到一个 使得在 这区间内所有的 。 由 泰勒展开 我们可以得知,在 区间内, 。 这样,我们就得到本方法的积分下限了: 其中最后一个等号来自于变数变换: 。请记得 ,所以我们才会对它的负号取开根号。 接着让我们对上面的不等式两边同除以 并且对 取极限,则 既然上式是对任意大于0的 都对,所以我们得到: 请注意,上面的证明也适用于 或 或双双跑到正负无限大的情况 上限 : 证明上限的部分其实和证明下限的部分很像,但是会较麻烦。再一次,我们取 ,不过,不再是任意而是多了一个要求 得够小以致于 。接着,就如同之前的证明,因着 被要求连续,并且根据 泰勒定理 我们会发现总存在一个 以至于在 区间里, 总是可以成立。 最后,在我们的假设里 (假设 都是有限值) ,由于 是全域最大所在处,我们总可以找到一个 使得所有在 这区间里, 总是成立。 现在,万事俱备,东风就在下面啦: 如果我们对上面的不等式两边皆除以 并且顺便取极限的话,会得到: 再一次,因为 可以取任意大于0的值,所以我们得到了上限了: 把上限与下限两个证明同时考虑,整个证明就完成了。 注意,关于上限的证明,很明显的当我们把它应用在 或 为正负无限大时,该上限证明会失败。那怎么办呢?我们需要再多假设一些东西。一个充分但非必要的假设是:当 时,此积分 为有限值,并且上面所说的 是存在的 (注意,当 区间是无限的时候,这假设是必要的) 。整个证明过程就如同先前所显示的那样,只不过下列的积分部分要做点改变: 必须利用上述的假设,而改为: 以取代先前会得到的 ,这样的话,当我们除以 ,就会改得到如下的结果: 这样的话,当我们取 时,上式的值就会趋近于 。而剩下的部分的证明就还是如同原先的证明,不做改变。 再强调一次,这里我们多加给无限大积分范围的情形的条件,是充分,但非必要。不过,这样的条件已经可以适用在许多情形了(但非全部)。 这考虑条件简单来讲就是积分区间得是被良好定义的(即不能是无限大的),并且被积函数在 必须是真的极大 (意即 必须真的存在) ;如果这积分区间是无限大的话,要求 时的此拉普拉斯方法所用的积分值要为有限并非必要的,其实只要当 大于某数时,此积分值会是有限的即可。 |
其他形式
有时拉普拉斯方法也会被写成其他形式,如:
其中 为正 (好像不必要)。
重要的是,这方法精确度与函数 和 有关。 [1] ***待考查***
相对误差的推导
|
|---|
|
首先,由于极大值所在设为 并不影响计算结果,所以以下的推导皆如此假设。此外,我们想要的是相对误差 ,所以 其中 ,所以,若我们令 且 ,则 所以,只要我们求得上式的上限为何,即可得相对误差。注意,这里的推导还可以再优化,不过,由于此处我只想显示它会收敛到0,因此,不再细推。 由于 ,因此 其中 与 雷同,所以只算 ,经过 的变换后,得到 也就是说,只要 取得够大,它就会趋近于0。 而 与 也雷同,所以也只算一个: 其中 并且 在此范围内要与 同号。 这里让我们选过 的切线为 吧!即 ,如图所示: 由图可以看出,当 或者 变小时,满足上列不等式的区间会变大,因此,为了涵盖整个区间, 有了上限。此外, 的积分也相对容易,因此,很适合用来预估误差。 由泰勒展开我们得知, 且 然后将它们代回 的计算里,不过,您可以看到,上述的两个余项皆与 的开根号成反比,为了式子的漂亮,让我省略它们吧!不省略只是看起来较丑陋而已,不过,那样子较严谨便是。 所以,原则上也是 越大则越趋近于0。只不过,在决定 的过程,设下了 的上限。 至于靠近极大值的点的积分,我们一样可以利用泰勒展开来求,当 在此点的一阶微分不为0时, 会看到它原则上与 的开根号成反比,其实,当 为常数时,积分出来的也会有如此的行为。 所以,概括的讲,靠近极大点的附近的积分原则上会随着 的增大而变小,而其余的部分,只要 够大,也会趋近于0,只是这 是有上限的,取决于我们所找的上限函数 是否在这区间内总是大于 ;不过,一旦有一个满足条件的 被找到,由于切线的起点为 ,因此, 可以取正比于 即可,所以, 越大, 也可以设越大。 |
至于多维的情形,让我们令 是一个 维向量,而 则是一个标量函数,则此拉普拉斯方法可以写成
其中的 是一个在 取值的 海森矩阵,而 则是指矩阵的 行列式 ;此外,与单变数的拉普拉斯方法类似,这里的 海森矩阵 必须为 负定矩阵,即该矩阵的所有本征值皆小于0,这样才会是极大值所在。.[2]
拉普拉斯方法的推广:最速下降法
此拉普拉斯方法可以被推广到 复分析 里头使用,搭配 留数定理 ,以找出一个过最速下降点的 contour (翻路径的话,会与path integral 相冲,所以,这里还是以英文原字称呼) 的 曲线积分 ,用来取代原有的复数空间的 contour积分。因为有时 的一阶微分为0的点未必就在实数轴上,而就算真在实数轴上,也未必二阶微分在 方向上为小于0 的实数;此种情况下,就得使用最速下降法了。由于最速下降法中,已经利用另一条通过最速下降的鞍点来取代原有的 contour 积分,经过变数变换后就会变得有如拉普拉斯方法,因此,我们可以透过这新的 contour ,找到原本的积分的渐进近似解,而这将大大的简化整个计算。就好像原本的路径像是在蜿蜒的山路开车,而新的路径就像干脆绕过这座山开,反正目的只是到达目的地而已,留数定理已经帮我们把中间的差都算好了。请读 Erdelyi (2012)与 Arfken & Weber (2005) 的书里有关 steepest descents 的章节。
以下就是该方法在z 平面下的形式:
其中 z0 就是新的路径通过的鞍点。 注意,开根号里的负号是用来指定最速下降的方向,千万别认为取 的绝对值来取代这个负号,若然,那就大错特错了。 另外要注意的是,如果该被积函数是 在手动语言转换规则中检测到错误 ,就有必要将被新旧 contour 包到的极点所贡献的留数给加入,范例请参考 Okounkov 的文章 arXiv:math/0309074 的第三章。
更进一步一般化
最速下降法还可以更进一步的推广到所谓的 非线性稳定相位/最速下降法 (nonlinear stationary phase/steepest descent method)。 这方法主要用在解非线性偏微分方程,透过将非线性偏微分方程转换为求解柯西变换(Cauchy transform)的积分形式,就可以借由最速下降法的想法来得到非线性解的渐进解。
以 艾里方程(线性) 为例,它可以写成积分形式如下:
由这条积分式,我们就可以借由最速下降法(若 指的是负实数轴,那么就回到此拉普拉斯方法了)来得到它的渐进解了。
然而,若方程式如 KdV方程 是个非线性偏微分方程,想要找到它的解相对应的一个复数 contour 积分的话,就没那么简单,在非线性稳定相位/最速下降法里所用到的概念主要是基于散射逆转换 (inverse scattering transform) 的处理方式,即先将原本的非线性偏微分方程变成 Lax 对 ,其中一个像是线性的 薛定谔方程式 ,其位能障为我们要找的 ,本征值为 ,波函数为 (不过,它并非我们所要的 );因此可以解它的散射矩阵,若利用解析延拓将原本的波函数由实数 延拓到复数空间时,就可以得到黎曼希尔伯特问题(RHP)的形式。利用这个黎曼希尔伯特问题(RHP) ,我们可以解得 的柯西变换的积分形式,再利用此线性薛定谔方程的特性,就可以反推出 的复数 contour 积分 形式了。
而 Lax 对 的另一个偏微分方程则是决定每个 随时间变化的行为,由于 在 时被要求为0 ,会发现整个偏微分方程会变得十分简单,并且只决定 里的 的值,不过,条件是 必须是指由正负无限远入射或反射波的解。这样,我们所得到的这个只与时间与本征值有关的系数 就可以直接被应用在上述的黎曼希尔伯特问题(RHP)里的跃变矩阵里了。
接着就是非线性稳定相位/最速下降法所要做的工作,即找出 鞍点 来,在该点附近基于最速下降法的精神做近似。不过,这近似因着考虑到收敛性,需要将原本的 contour 变形,与将原本的黎曼希尔伯特问题(RHP)作转换,所以有再比原本的最速下降法多出一些步骤来。
这整个方法最早由 Deift 与 Zhou 在 1993 基于 Its 之前的工作所提出的,后续又有许多人加以改进,主要的应用则有 孤波 理论,可积模型等。
复数积分
以下的积分常用在 拉普拉斯变换#拉普拉斯逆变换 里,
假定我们想要得到该积分在 时的结果(若 为时间,通常就是在找经过够久时间后达稳定的结果),我们可以透过 解析延拓 的概念,先将这时间换成虚数,如 t = iu 并且一并做 的变换,则我们可以将上式转换为如下的 拉普拉斯变换#双边拉普拉斯变换
这里就可以套用此拉普拉斯方法求渐进解,最后,再利用 u = t / i 把 t 换回来,就可以得到该拉普拉斯逆变换的渐进解了。
例子1:斯特灵公式
拉普拉斯方法可以用在推导 斯特灵公式 上;当 N 很大时,
证明:
由 Γ函数 的积分定义,我们可以得到
接着让我们做变数变换,
因此
将这些代回 Γ函数 的积分定义里,我们可以得到
经由此变数变换后,我们有了拉普拉斯方法所需要的 为
而它乃为二次可微函数,且
因此, ƒ(z) 的极大值出现在 z0 = 1 而且在该点的二次微分为 。因此,我们得到
例子2:贝氏网络 ,参数估计与概率推理
关于概率推理的简介,请参考 http://doc.baidu.com/view/e9c1c086b9d528ea81c77989.html 。 而在 Azevedo-Filho & Shachter 1994 的文章里,则回顾了如何应用此拉普拉斯方法 (无论是单变数或者多变数) 如何应用在 概率推理 上,以加速得到系统的 后验矩 (数学) (posterior moment) , 贝氏参数 等,并举医学诊断上的应用为例。
相关维基百科文章
参考文献
- ^ Butler, Ronald W. Saddlepoint approximations and applications. Cambridge University Press. 2007. ISBN 978-0-521-87250-8.
- ^ MacKay, David J. C. Information Theory, Inference and Learning Algorithms. Cambridge: Cambridge University Press. September 2003. ISBN 9780521642989. (原始内容存档于2016-02-17).
- Deift, P.; Zhou, X., A steepest descent method for oscillatory Riemann–Hilbert problems. Asymptotics for the MKdV equation, Ann. of Math. 137 (2), 1993, 137 (2): 295–368, doi:10.2307/2946540.
- Azevedo-Filho, A.; Shachter, R., Laplace's Method Approximations for Probabilistic Inference in Belief Networks with Continuous Variables, Mantaras, R.; Poole, D. (编), Uncertainty in Artificial Intelligence, San Francisco, CA: Morgan Kauffman, 1994, CiteSeerX: 10.1.1.91.2064 .
- Erdelyi, A., Asymptotic Expansions, Dover Publications, 2012, ISBN 9780486155050.
- Arfken, G.B.; Weber, H.J., Mathematical Methods For Physicists International Student Edition, Elsevier Science, 2005, ISBN 9780080470696.