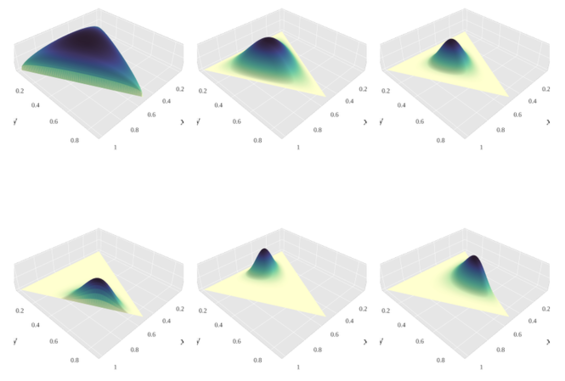
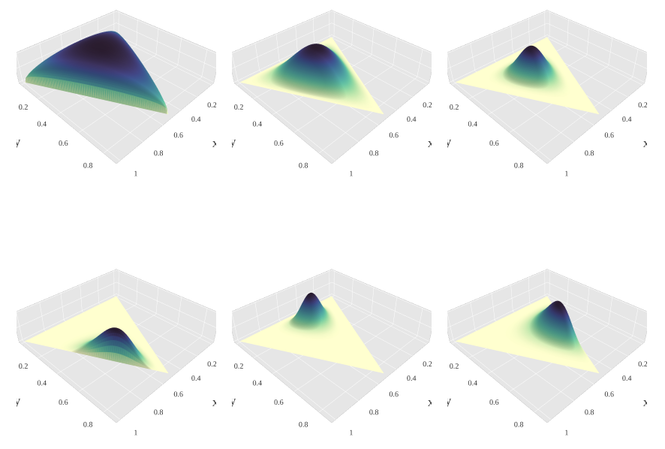
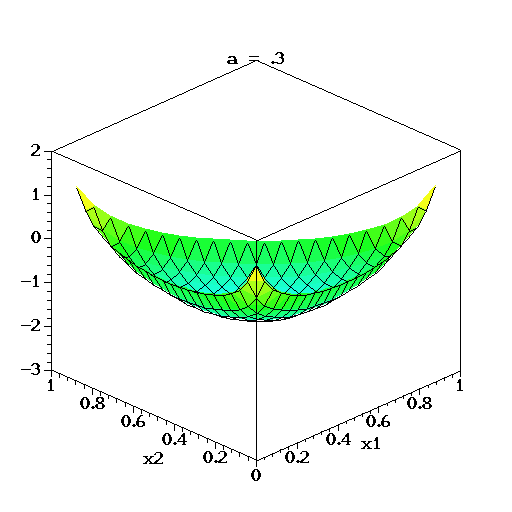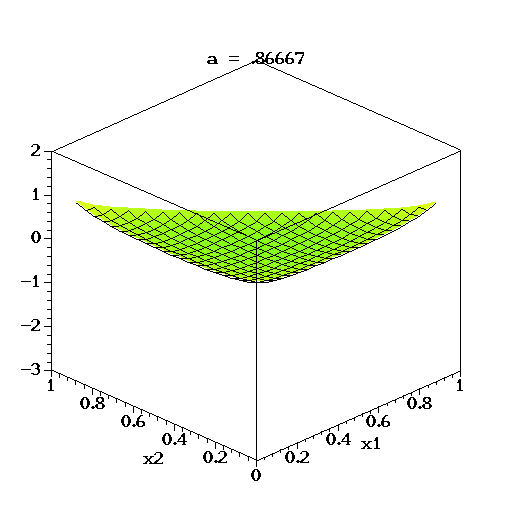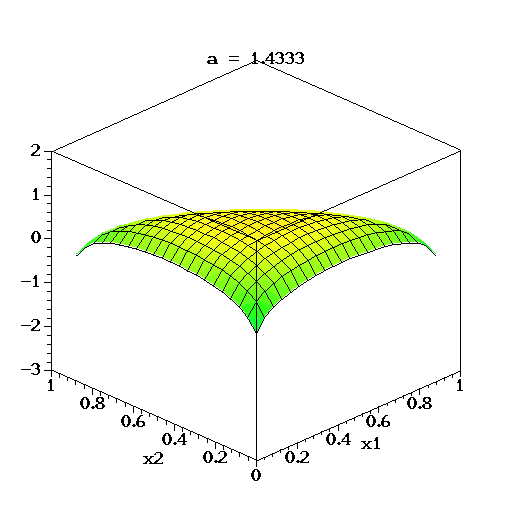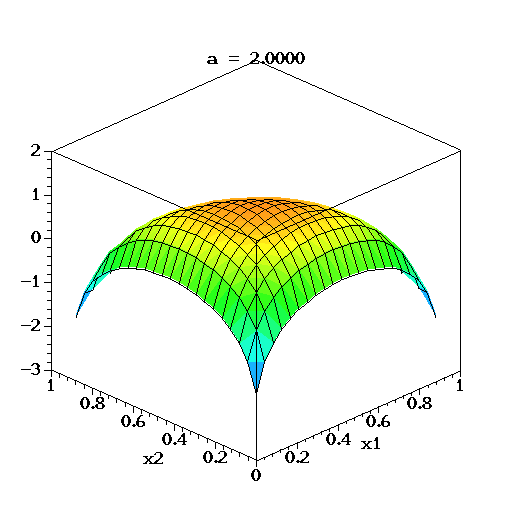
狄利克雷分布狄利克雷分布是一组连续多变量概率分布,是多变量普遍化的Β分布。为了纪念德国数学家约翰·彼得·古斯塔夫·勒热纳·狄利克雷(Peter Gustav Lejeune Dirichlet)而命名。狄利克雷分布常作为贝叶斯统计的先验概率。当狄利克雷分布维度趋向无限时,这过程便称为狄利克雷过程(Dirichlet process)。 狄利克雷分布 概率密度函数参数 K ≥ 2 {\displaystyle K\geq 2} 分类数 (整数) α 1 , … , α K {\displaystyle \alpha _{1},\ldots ,\alpha _{K}} concentration parameters, α i > 0 {\displaystyle \alpha _{i}>0} 值域 x 1 , … , x K {\displaystyle x_{1},\ldots ,x_{K}} , x i ∈ ( 0 , 1 ) {\displaystyle x_{i}\in (0,1)} , ∑ i = 1 K x i = 1 {\displaystyle \sum _{i=1}^{K}x_{i}=1} 概率密度函数 1 B ( α ) ∏ i = 1 K x i α i − 1 {\displaystyle {\frac {1}{\mathrm {B} ({\boldsymbol {\alpha }})}}\prod _{i=1}^{K}x_{i}^{\alpha _{i}-1}} B ( α ) = ∏ i = 1 K Γ ( α i ) Γ ( ∑ i = 1 K α i ) {\displaystyle \mathrm {B} ({\boldsymbol {\alpha }})={\frac {\prod _{i=1}^{K}\Gamma (\alpha _{i})}{\Gamma {\bigl (}\sum _{i=1}^{K}\alpha _{i}{\bigr )}}}} α = ( α 1 , … , α K ) {\displaystyle {\boldsymbol {\alpha }}=(\alpha _{1},\ldots ,\alpha _{K})} 期望值 E [ X i ] = α i ∑ k α k {\displaystyle \operatorname {E} [X_{i}]={\frac {\alpha _{i}}{\sum _{k}\alpha _{k}}}} E [ ln X i ] = ψ ( α i ) − ψ ( ∑ k α k ) {\displaystyle \operatorname {E} [\ln X_{i}]=\psi (\alpha _{i})-\psi (\textstyle \sum _{k}\alpha _{k})} (试看 digamma function)众数 x i = α i − 1 ∑ k = 1 K α k − K , α i > 1. {\displaystyle x_{i}={\frac {\alpha _{i}-1}{\sum _{k=1}^{K}\alpha _{k}-K}},\quad \alpha _{i}>1.} 方差 Var [ X i ] = α ~ i ( 1 − α ~ i ) α ¯ + 1 , {\displaystyle \operatorname {Var} [X_{i}]={\frac {{\tilde {\alpha }}_{i}(1-{\tilde {\alpha }}_{i})}{{\bar {\alpha }}+1}},} 其中 α ~ i = α i ∑ i = 1 K α i {\displaystyle {\tilde {\alpha }}_{i}={\frac {\alpha _{i}}{\sum _{i=1}^{K}\alpha _{i}}}} 而且 α ¯ = ∑ i = 1 K α i {\displaystyle {\bar {\alpha }}=\sum _{i=1}^{K}\alpha _{i}} Cov [ X i , X j ] = − α ~ i α ~ j α ¯ + 1 ( i ≠ j ) {\displaystyle \operatorname {Cov} [X_{i},X_{j}]={\frac {-{\tilde {\alpha }}_{i}{\tilde {\alpha }}_{j}}{{\bar {\alpha }}+1}}~~(i\neq j)} 熵 H ( X ) = log B ( α ) + ( α 0 − K ) ψ ( α 0 ) − ∑ j = 1 K ( α j − 1 ) ψ ( α j ) {\displaystyle H(X)=\log \mathrm {B} (\alpha )+(\alpha _{0}-K)\psi (\alpha _{0})-\sum _{j=1}^{K}(\alpha _{j}-1)\psi (\alpha _{j})} 狄利克雷分布奠定了狄利克雷过程的基础,被广泛应用于自然语言处理特别是主题模型(topic model)的研究。 概率密度函数 此图展示了当K=3、参数α从α=(0.3, 0.3, 0.3)变化到(2.0, 2.0, 2.0)时,密度函数取对数后的变化。 维度K ≥ 2的狄利克雷分布在参数α1, ..., αK > 0上、基于欧几里得空间RK-1里的勒贝格测度有个概率密度函数,定义为: f ( x 1 , … , x K ; α 1 , … , α K ) = 1 B ( α ) ∏ i = 1 K x i α i − 1 {\displaystyle f(x_{1},\dots ,x_{K};\alpha _{1},\dots ,\alpha _{K})={\frac {1}{\mathrm {B} (\alpha )}}\prod _{i=1}^{K}x_{i}^{\alpha _{i}-1}} 其中 x {\displaystyle {\boldsymbol {x}}} 满足 ∑ i = 1 K x i = 1 {\displaystyle \sum _{i=1}^{K}x_{i}=1} ,同时对于任意 i ∈ { 1 , … , K } {\displaystyle i\in \{1,\dots ,K\}} ,都有 x i ≥ 0 {\displaystyle x_{i}\geq 0} 。即 x {\displaystyle {\boldsymbol {x}}} 在(K − 1)维的单纯形开集上密度为0。 归一化衡量B(α)是多项Β函数,可以用Γ函数(gamma function)表示: B ( α ) = ∏ i = 1 K Γ ( α i ) Γ ( ∑ i = 1 K α i ) , α = ( α 1 , … , α K ) . {\displaystyle \mathrm {B} (\alpha )={\frac {\prod _{i=1}^{K}\Gamma (\alpha _{i})}{\Gamma {\bigl (}\sum _{i=1}^{K}\alpha _{i}{\bigr )}}},\qquad \alpha =(\alpha _{1},\dots ,\alpha _{K}).} 参见 约翰·彼得·古斯塔夫·勒热纳·狄利克雷 狄利克雷过程 隐含狄利克雷分布参考 Introduction to the Dirichlet Distribution and Related Processes by Frigyik, Kapila and Gupta Dirichlet processes by Yee Whye Teh
 分类数 (整数)
分类数 (整数) concentration parameters,
concentration parameters,
 ,
, ,
,



![{\displaystyle \operatorname {E} [X_{i}]={\frac {\alpha _{i}}{\sum _{k}\alpha _{k}}}}](/media/math_img/1272/fba3f45d2d1945a428884b57067ac66a7481ad10.svg)
![{\displaystyle \operatorname {E} [\ln X_{i}]=\psi (\alpha _{i})-\psi (\textstyle \sum _{k}\alpha _{k})}](/media/math_img/1272/af11020481980cb1aa891045a0f07ebb172ccd3d.svg)

![{\displaystyle \operatorname {Var} [X_{i}]={\frac {{\tilde {\alpha }}_{i}(1-{\tilde {\alpha }}_{i})}{{\bar {\alpha }}+1}},}](/media/math_img/1272/1dcbe495dc40c027cddad9a86e472c5cfe743d98.svg)


![{\displaystyle \operatorname {Cov} [X_{i},X_{j}]={\frac {-{\tilde {\alpha }}_{i}{\tilde {\alpha }}_{j}}{{\bar {\alpha }}+1}}~~(i\neq j)}](/media/math_img/1272/65dbd8e453a3b436c855934f7252874184badd96.svg)

{kind=link}