关联数组
在计算机科学中,关联数组(英语:Associative Array),又称映射(Map)、字典(Dictionary)是一个抽象的数据结构,它包含着类似于(键,值)的有序对。一个关联数组中的有序对可以重复(如C++中的multimap)也可以不重复(如C++中的map)。
这种数据结构包含以下几种常见的操作:
字典问题是设计一种能够具备关联数组特性的数据结构。解决字典问题的常用方法,是利用散列表或查找树[1][2][3][4]。有些情况下,也可以使用直接寻址的数组、二叉查找树或其他专门的结构。
关联数组有许多应用,包括诸如记忆化和修饰模式的编程模式。[5]
许多程序设计语言内置基本的数据类型,提供对关联数组的支持。而内容寻址存储器则是硬件层面上实现对关联数组的支持。
操作
关联数组中,键与值的关联通常称作“映射”,“映射”一词也指创建新的关联的过程。
- 添加或插入:添加一个新的键值对,创建从新键到新值的映射。该操作的参数是要添加的键和值。
- 重新赋值:更改一已有的键值对的值,把原有的键映射到新的值。和插入一样,参数为键和值。
- 删除:移除一个键值对,取消从该键到该值的映射。参数为要删除的键。
- 查询:查找到给出键对应的值(如果该键存在)。这个操作的参数是要查找的键,返回的是对应的值。如果没有相应的键值对,有些实现会引发异常,而另外一些则会使用所给的键创建并添加新的键值对,其中的“值”为其类型的默认值(零、空容器等)
添加和重新赋值的操作常作为一个赋值的操作出现,即如果存在键值对则更新它,反之添加。
关联数组也可能包括其他操作,比如查询已有的映射数目和构造迭代器以遍历所有映射。遍历的顺序通常由关联数组的实现决定。
示例
假设需要在一种数据结构中表示图书馆的借书情况。一本书一次只能借给一位读者,但一位读者同时可以借阅多本书。因此有关哪本书被哪位读者借出的信息可以用关联数组表示。这个数据结构用Python或JSON的记法可以表示如下:
{
"傲慢与偏见": "小红",
"呼啸山庄": "小红",
"远大前程": "小李"
}
对键“远大前程”的查询操作会返回“小李”。如果小李还了书,就需要一个删除操作。如果小陈外借了一本书,就需要一个插入操作,导致关联数组更新:
{
"傲慢与偏见": "小明",
"卡拉马佐夫兄弟": "小陈",
"呼啸山庄": "小红"
}
实现
对于非常小的关联数组来说,使用关联列表,即以映射为节点的链表实现较为合理。在这种实现下,进行基本操作的时间与映射的总数呈线性关系。但是这样的实现难度低、运行时间中的常数小,因此仍为较好的选择。[1][7]
在键仅限于较窄范围时,还有另外一种简单的实现技巧。可以将键直接用于数组的寻址:比如键k对应的值就储存在数组元素A[k],如果k还没有映射,那么在A[k]存储一个特殊的哨兵值来表示。这种实现既简单又很快,每个操作只需要常数时间。其不足之处在于需要相当于整个键空间的储存空间,这意味着除非键空间很小,这种方法并不实用。
实现关联数组的主要方法是散列表和搜索树。[1][2][3][4]
散列表实现
{kind=link}
关联数组最常用的通用实现是使用散列表——数组和散列函数的结合。该散列函数把每个键分散到各自的“桶”中。散列表背后的基本原理是:用下标访问数组是一个简单的常数时间的操作。因此对散列表的操作所需的平均开销只包括计算散列值,和在数组中访问对应的“桶”。正因如此,使用散列表的时间复杂度通常为O(1),大多数情况下优于其他方法。
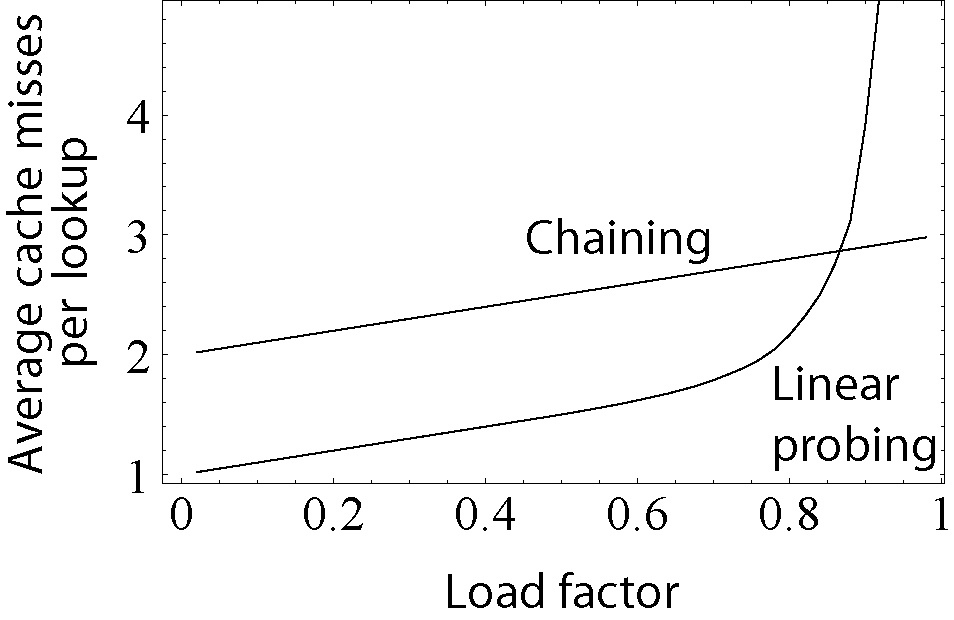
散列表需要能处理冲突——散列函数把两个不同的键映射到同一个“桶”的情况。解决这个问题的两个最普遍的方法是单独链表法和开放寻址法。[1][2][3][8]单独链表法中,数组不是直接储存值本身,而是储存一个指向另一个容器的指针。这个容器常常是一个关联表,储存着对应同个散列值的所有值。而在开放寻址法中如果出现散列冲突,散列表会在数组中决定性地找到一个空位,通常就是查看邻近的下一个位置。
当散列表大部分空着时,开放寻址法比单独链表法有着更低的缓存不命中率。但是随着散列表被更多的元素填充,开放寻址法的性能指数级地下降。此外,单独链表法使用的内存在多数情况下更少,除非值的大小非常小(小于四倍的指针大小)。
树实现
自平衡二叉搜索树
实现关联数组另一个常用的方法是使用自平衡二叉搜索树,例如AVL树或红黑树。[9]
与使用散列表相比,使用树有其优点和不足。就最坏情况而言,自平衡二叉搜索树远好于散列表。使用自平衡二叉树的最坏情况的时间复杂度用大O表示法表示,为O(log n)。相比之下,使用散列表的最坏情况的时间复杂度则为O(n)。此外,和所有二叉搜索树一样,自平衡二叉搜索树中的元素始终按顺序排列。因此,对使用树实现的关联数组的遍历是按从小到大的顺序进行的,而遍历散列表则会呈现看似随机的序列。然而,散列表平均情况的时间复杂度(O(1))比树要好得多,而且若散列函数选择恰当,最坏情况出现的概率很小。
值得注意的是,自平衡二叉搜索树也可以用来实现采用单独链表法的散列表的“桶”。这种实现保留了散列表的常数查询时间,且保证最坏情况也有O(log n)的表现。但是这种做法给实现增添了额外的复杂性且可能降低小型散列表的性能,因为在较小的散列表里,在树中插入元素并维护树的平衡所需的时间会长于直接对链表或类似数据结构中进行线性搜索所需的时间。[10][11]
各语言 / 库中的支持
关联数组的内置语法上的支持是在1969年由SNOBOL4最早介入的,当时名字叫做“表格”。TMG提供带有字符串键和整数值的表格。MUMPS将多维关联数组作为它的关键数据结构,带有可选的持久性。SETL支持它们作为集合和映射的一种可能实现。
C++(标准模板库)
STL 提供了 8 个关联数组容器模板:
| 类模板 | 说明 |
|---|---|
| std::map<K, V> std::unordered_map<K, V> |
从 K 到 V 类型的一对一字典 不带 unordered_ 前缀的为根据 K 排序的红黑树、带前缀的为散列表(即不排序,故名) |
| std::multimap<K, V> std::unordered_multimap<K, V> |
从 K 到 V 的一对多字典 |
| std::set<T> std::unordered_set<T> |
T 的集合 |
| std::multiset<T> std::unordered_multiset<T> |
T 的多重集 |
.Net Framework
C++/CLI 中另有 .Net 所提供的托管实现,见下。
| 类 / 接口 | 说明 |
|---|---|
| System.Collections.IDictionary System.Collections.Generic.IDictionary<K, V> |
字典的接口 System.Collections 名字空间中为非泛型版本,即其内容类型为 System.Object 类型 |
| System.Collections.HastTable System.Collections.Generic.Dictionary<K, V> |
散列表实现的字典 |
| System.Collections.Generic.SortedDictionary<K, V> | 二叉搜索树 |
| System.Collections.SortedList System.Collections.Generic.SortedList<K, V> |
按键排序的数组 |
参考
- ^ 1.0 1.1 1.2 1.3 1.4 1.5 Goodrich, Michael T.; Tamassia, Roberto, 9.1 The Map Abstract Data Type, Data Structures & Algorithms in Java 4th, Wiley: 368–371, 2006.
- ^ 2.0 2.1 2.2 2.3 2.4 Mehlhorn, Kurt; Sanders, Peter, 4 Hash Tables and Associative Arrays, Algorithms and Data Structures: The Basic Toolbox, Springer: 81–98, 2008
- ^ 3.0 3.1 3.2 Cormen, Thomas H.; Leiserson, Charles E.; Rivest, Ronald L.; Stein, Clifford, 11 Hash Tables, Introduction to Algorithms 2nd, MIT Press and McGraw-Hill: 221–252, 2001, ISBN 0-262-03293-7 .
- ^ 4.0 4.1 Dietzfelbinger, M., Karlin, A., Mehlhorn, K., Meyer auf der Heide, F., Rohnert, H., and Tarjan, R. E. 1994. "Dynamic Perfect Hashing: Upper and Lower Bounds" 互联网档案馆的存档,存档日期2016-03-04.. SIAM J. Comput. 23, 4 (Aug. 1994), 738-761. http://portal.acm.org/citation.cfm?id=182370 doi:10.1137/S0097539791194094
- ^ Goodrich & Tamassia (2006), pp. 597–599.
- ^ Goodrich & Tamassia (2006), pp. 389–397.
- ^ When should I use a hash table instead of an association list?. lisp-faq/part2. 1996-02-20 [2021-08-26]. (原始内容存档于2022-03-31).
- ^ Klammer, F.; Mazzolini, L., Pathfinders for associative maps, Ext. Abstracts GIS-l 2006, GIS-I: 71–74, 2006.
- ^ Joel Adams and Larry Nyhoff. "Trees in STL" (页面存档备份,存于互联网档案馆). Quote: "The Standard Template library ... some of its containers -- the set<T>, map<T1, T2>, multiset<T>, and multimap<T1, T2> templates -- are generally built using a special kind of self-balancing binary search tree called a red–black tree."
- ^ Knuth, Donald. The Art of Computer Programming. 3: Sorting and Searching 2nd. Addison-Wesley. 1998: 513–558. ISBN 0-201-89685-0.
- ^ Probst, Mark. Linear vs Binary Search. 2010-04-30 [2016-11-20]. (原始内容存档于2016-11-20).