隐马尔可夫模型
| 此条目需要补充更多来源。 (2015年7月3日) |
隐马尔可夫模型(Hidden Markov Model;缩写:HMM)或称作隐性马尔可夫模型,是统计模型,它用来描述一个含有隐含未知参数的马尔可夫过程。其难点是从可观察的参数中确定该过程的隐含参数。然后利用这些参数来作进一步的分析,例如模式识别。
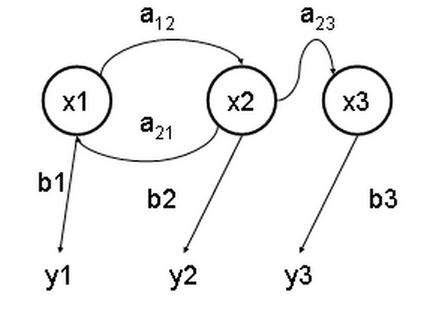
在正常的马尔可夫模型中,状态对于观察者来说是直接可见的。这样状态的转换概率便是全部的参数。而在隐马尔可夫模型中,状态并不是直接可见的,但受状态影响的某些变量则是可见的。每一个状态在可能输出的符号上都有一概率分布。因此输出符号的序列能够透露出状态序列的一些信息。
马尔可夫模型的演化
下边的图示强调了HMM的状态变迁。有时,明确的表示出模型的演化也是有用的,我们用 x(t1) 与 x(t2) 来表达不同时刻 t1 和 t2 的状态。
图中箭头方向则表示不同信息间的关系性,因此可以得知 和 有关,而 又和 有关。
而每个 只和 有关,其中 我们称为隐藏变量(hidden variable),是观察者无法得知的变量。
隐性马尔可夫模型常被用来解决有未知条件的数学问题。
假设隐藏状态的值对应到的空间有 个元素,也就是说在时间 时,隐藏状态会有 种可能。
同样的, 也会有 种可能的值,所以从 到 间的关系会有 种可能。
除了 间的关系外,每组 间也有对应的关系。
若观察到的 有 种可能的值,则从 到 的输出模型复杂度为 。如果 是一个 维的向量,则从 到 的输出模型复杂度为 。
{kind=link}
在这个图中,每一个时间块(x(t), y(t))都可以向前或向后延伸。通常,时间的起点被设置为t=0 或 t=1.
马尔可夫模型的概率
假设观察到的结果为
隐藏条件为
长度为 ,则马尔可夫模型的概率可以表达为:
由这个概率模型来看,可以得知马尔可夫模型将该时间点前后的信息都纳入考量。
使用隐马尔可夫模型
HMM有三个典型(canonical)问题:
- 预测(filter):已知模型参数和某一特定输出序列,求最后时刻各个隐含状态的概率分布,即求 。通常使用前向算法解决。
- 平滑(smoothing):已知模型参数和某一特定输出序列,求中间时刻各个隐含状态的概率分布,即求 。通常使用前向-后向算法解决。
- 解码(most likely explanation):已知模型参数,寻找最可能的能产生某一特定输出序列的隐含状态的序列,即求 。通常使用Viterbi算法解决。
此外,已知输出序列,寻找最可能的状态转移以及输出概率.通常使用Baum-Welch算法以及Viterbi algorithm解决。另外,最近的一些方法使用联结树算法来解决这三个问题。 [来源请求]
具体实例
假设你有一个住得很远的朋友,他每天跟你打电话告诉你他那天做了什么。你的朋友仅仅对三种活动感兴趣:公园散步,购物以及清理房间。他选择做什么事情只凭天气。你对于他所住的地方的天气情况并不了解,但是你知道总的趋势。在他告诉你每天所做的事情基础上,你想要猜测他所在地的天气情况。
你认为天气的运行就像一个马尔可夫链。其有两个状态“雨”和“晴”,但是你无法直接观察它们,也就是说,它们对于你是隐藏的。每天,你的朋友有一定的概率进行下列活动:“散步”、“购物”、“清理”。因为你朋友告诉你他的活动,所以这些活动就是你的观察数据。这整个系统就是一个隐马尔可夫模型(HMM)。
你知道这个地区的总的天气趋势,并且平时知道你朋友会做的事情。也就是说这个隐马尔可夫模型的参数是已知的。你可以用程序语言(Python)写下来:
states = ('Rainy', 'Sunny')
observations = ('walk', 'shop', 'clean')
start_probability = {'Rainy': 0.6, 'Sunny': 0.4}
transition_probability = {
'Rainy' : {'Rainy': 0.7, 'Sunny': 0.3},
'Sunny' : {'Rainy': 0.4, 'Sunny': 0.6},
}
emission_probability = {
'Rainy' : {'walk': 0.1, 'shop': 0.4, 'clean': 0.5},
'Sunny' : {'walk': 0.6, 'shop': 0.3, 'clean': 0.1},
}
在这些代码中,start_probability代表了你对于你朋友第一次给你打电话时的天气情况的不确定性(你知道的只是那个地方平均起来下雨多些)。在这里,这个特定的概率分布并非平衡的,平衡概率应该接近(在给定变迁概率的情况下){'Rainy': 0.571, 'Sunny': 0.429}。
transition_probability 表示基于马尔可夫链模型的天气变迁,在这个例子中,如果今天下雨,那么明天天晴的概率只有30%。代码emission_probability 表示了你朋友每天做某件事的概率。如果下雨,有50% 的概率他在清理房间;如果天晴,则有60%的概率他在外头散步。
这个例子在维特比算法页上有更多的解释。
隐马尔可夫模型的应用
- 语音识别、中文断词/分词或光学字符识别
- 机器翻译
- 生物信息学 和 基因组学
- 基因组序列中蛋白质编码区域的预测
- 对于相互关联的DNA或蛋白质族的建模
- 从基本结构中预测第二结构元素
- 通信中的译码过程
- 地图匹配算法
- 还有更多...
隐马尔可夫模型在语音处理上的应用
因为马尔可夫模型有下列特色:
- 时间点 的隐藏条件和时间点 的隐藏条件有关。因为人类语音拥有前后的关系,可以从语义与发音两点来看:
- 单字的发音拥有前后关系:例如"They are"常常发音成"They're",或是"Did you"会因为"you"的发音受"did"的影响,常常发音成"did ju",而且语音识别中用句子的发音来进行分析,因此需要考虑到每个音节的前后关系,才能够有较高的准确率。
- 句子中的单字有前后关系:从英文文法来看,主词后面常常接助动词或是动词,动词后面接的会是受词或介系词。而或是从单一单字的使用方法来看,对应的动词会有固定使用的介系词或对应名词。因此分析语音频息时需要为了提升每个单字的准确率,也需要分析前后的单字。
- 马尔可夫模型将输入消息视为一单位一单位,接着进行分析,与人类语音模型的特性相似。语音系统识别的单位为一个单位时间内的声音。利用梅尔倒频谱等语音处理方法,变换成一个发音单位,为离散型的信息。而马尔可夫模型使用的隐藏条件也是一个个被数据包的 ,因此使用马尔可夫模型来处理声音频号比较合适。
历史
隐马尔可夫模型最初是在20世纪60年代后半期Leonard E. Baum和其它一些作者在一系列的统计学论文中描述的。HMM最初的应用之一是开始于20世纪70年代中期的语音识别。[1]
在1980年代后半期,HMM开始应用到生物序列尤其是DNA的分析中。此后,在生物信息学领域HMM逐渐成为一项不可或缺的技术。[2]
参见
注解
参考书目
- Lawrence R. Rabiner, A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition. Proceedings of the IEEE, 77 (2), p. 257–286, February 1989.
- Richard Durbin, Sean R. Eddy, Anders Krogh, Graeme Mitchison. Biological Sequence Analysis: Probabilistic Models of Proteins and Nucleic Acids. Cambridge University Press, 1999. CiteSeer: [1] (页面存档备份,存于互联网档案馆))
- http://www.comp.leeds.ac.uk/roger/HiddenMarkovModels/html_dev/main.html (页面存档备份,存于互联网档案馆)
- J. Li (页面存档备份,存于互联网档案馆), A. Najmi, R. M. Gray, Image classification by a two dimensional hidden Markov model, IEEE Transactions on Signal Processing, 48(2):517-33, February 2000.
- 隐马尔可夫模型(课件), 徐从富,浙江大学人工智能研究所 [2]
外部链接
- Hidden Markov Model (HMM) Toolbox for Matlab (by Kevin Murphy)
- Hidden Markov Model Toolkit (HTK) (页面存档备份,存于互联网档案馆) (a portable toolkit for building and manipulating hidden Markov models)
- Hidden Markov Models (页面存档备份,存于互联网档案馆) (an exposition using basic mathematics)
- GHMM Library (页面存档备份,存于互联网档案馆) (home page of the GHMM Library project)
- Jahmm Java Library (Java library and associated graphical application)
- A step-by-step tutorial on HMMs (页面存档备份,存于互联网档案馆) (University of Leeds)
- Software for Markov Models and Processes (TreeAge Software)